Cassandra, мой первый кластер и первая NoSQL
Добрый день, я - Алексей Зиновьев [Alexey Zinoviev], человек, на пути которого встала NoSQL Cassandra.
Соцсоревнование NoSQL
Один из производителей NoSQL СУБД заказал независимое исследование, мол, какая NoSQL круче.Каждому участнику раздали по одной СУБД, мне же досталась Cassandra.
Задача передо мною была поставлена следующая: развернуть кластер Cassandra сначала на тестовых серверах Amazon, а затем на оборудовании, предоставленном заказчиком эксперимента. А также найти оптимальные настройки.
После этого необходимо было погонять тесты производительности эмулирующие максимальную нагрузку на кластеры. Именно максимальную, т.е. всех интересовало, как себя кластеры будут вести при пиковых нагрузках, насколько сильно велик будет процент криво записанных данных, падение среднего отклика и т.п.
Для тестирования производительности YCSB, среди которых есть стандартная реализация и для Cassandra. В состав тестов YCSB входят загрузка большого числа данных, чтение и запись в разных пропорциях. Можно настроить это соотношение, скорость записи, некоторую статистику, тип вывода информации (гистограмма или линейный вывод). Измеряется в ходе тестов latency - время отклика системы на некое действие.
YCSB написан на java, как и Cassandra, поэтому на клиенте необходимо установить Java 6 или 7 (OpenJDK на худой конец) и пошаманить с настройками JVM.
Бомбить кластер мы планировали с 2 или 4 клиентов, каждый из которых на деле являлся скорее frontend-сервером, который уже грубо долбит backend в виде кластера. На каждом клиенте запускались из собственной консоли YCSB тесты с определенным набором параметров.
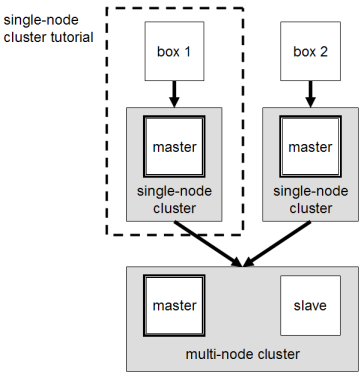
Т.е. самым сложным для меня было разобраться с созданием и настройкой кластера из 4 узлов.
Под Windows это все не пашет, пришлось познакомиться с Virtual Box и поставить на нее Ubuntu 12.04 Server.
Какие ресурсы помогли мне справиться с задачей?
В первую очередь это отличное официальное руководство. Много полезного и русскоязычного нашел в статье с хабра. Там есть основная инфа и грех ее пересказывать. Есть кое - какие сведения о настройках.Есть отличная pdf-ка c документацией.
Для того, чтобы написать простейшие запросы отлично подойдет руководство по языку запросов CQL. CQL - вообще забавный язык, учится за 1 час. Если вы не любили многоуровневые запросы на SQL, вам он очень понравится - в наборе простейший SELECT, UPDATE, CREATE, DELETE, INSERT, работа с индексами. И некие keyspaces, дико напоминающие старые добрые реляционные таблицы.
Почему я выбрал Cassandra?
Среди всех NoSQL СУБД меня привлекала Cassandra хоть какой - то возможностью иногда навязать схему данных.В моих задачах, связанных с дорожным графом, данные выглядят просто, несколько сущностей, но их, как вы понимаете, очень много.
Развертывание кластера
Алгоритм развертывания кластера, основано на (с учетом проб и ошибок) http://wiki.apache.org/cassandra/MultinodeCluster- Приложение с тестами YCSB будет общаться с кластером через протокол Thrift.
- Необходимо на каждой ноде [узле] нового кластера установить Cassandra, просто распаковав в каталог.
- Далее, нужно узнать ip-адреса каждой ноды [узла] и запомнить их.
- Необходимо исправить настройки на каждой ноде [узла] в конфигурационном файле в Cassandra/conf/cassandra.yaml, причем придется выбрать ноду [узел], которая будет точкой входа и ее ip - будет главным для подключения с клиента (на самом деле frontend - сервера).
- Кластер организуется по типу "кольцо"; чтобы проверить, что кластер организовался - необходимо исполнить команду nodetool ring. Если все хорошо, то можно увидеть таблицу, где сидят и ждут insert-ов 4 ноды [узла] .
Изменения в каждом файле настроек cassandra.yaml:
- В самом первом (входной точке) находим свойства listen_address, rpc_address, seeds: и указываем его ip. Назовем его HeadIP.
- В остальных мы изменяем свойства listen_address, rpc_address: - указывая ip ноды [узла].
- А вот в свойстве seeds: указываем HeadIP. Таким образом все остальные ноды [узлы] узнают о точке входа с HeadIP.
- Если что-то не так, перезапустите везде Cassandra, начиная с первой ноды [узла]. "Кольцо" соберется само.
Для прогона тестов нужно вручную создать схему БД (на любом узле кластера). В исходниках YCSB не рассказывается, какую схему нужно создать, а ведь без нее тесты не работают.
Набор команд:
cassandra-cli -host <ip_address> -port 9160 // Подключение к протоколу Thrift
Тут вы попадете в особенную console CLI, где всякий оператор должен заканчиваться при помощи ";".
CREATE KEYSPACE usertable //Судя по исходникам YCSB
WITH placement_strategy = 'org.apache.cassandra.locator.SimpleStrategy'
AND strategy_options = {replication_factor:2}; // Нам нужна репликация (двукратная)
use usertable;
CREATE COLUMN FAMILY data
WITH comparator = UTF8TypeAND key_validation_class=UTF8Type
AND column_metadata = [
{column_name: age, validation_class: UTF8Type}
{column_name: middlename, validation_class: UTF8Type}
{column_name: favoritecolor, validation_class: UTF8Type}
]; //Судя по исходникам YCSB
Также вы можете для своих тестов из консоли управлять кластером, обратите ваше внимание на команды, начинающиеся на nodetool (хорошая утилита).
Изменить состав кластера можно при помощи nodetool removetoken и nodetool move.
Если вы меняете какие - то настройки, то чаще всего надо будет запускать заново кластер и чистить данные на дисках. Это очень грустный момент для экспериментирующих.
Мои рекомендации по обходу подводных камней и простейшие настройки Cassandra
"Cassandra
супер-быстра на запись. Обеспечивается это тем что данные попадают в
таблицу в памяти, и в commit log, что означает: запись на диск всегда
идёт последовательно, какие-либо существенные перемещения по диску
отсутствуют ( поэтому commit log и таблицы, к которым происходит
случайный доступ, рекомендуется держать на разных дисках).
Кассандре в обычном режиме работы (отсутствие compaction, добавление нового узла) нужно иметь запас как минимум 50% диска, потому что ближайший compaction может временно удвоить, а процесс repair в неудачных случаях и утроить потребляемое место. Поэтому мы взяли обьем диска с тройным запасом (у нас получились 300G)" - это отсюда.
Следовательно, необходимо указать разные директории для
commitlog_directory и data_file_directories, saved_caches_directory.
commitlog_sync_period_in_ms = 100000, а не 10 000 (реже сбрасываем на диск)
Это в файликах Cassandra/conf/cassandra.yaml
Также стоит исправить в файлике Cassandra/conf/cassandra-env.sh параметры (лучше на всех узлах). Эти настройки важны для JVM [Java Virtual Machine].
MAX_HEAP_SIZE = “15G” - 1/2 от доступной памяти на каждом узле.
HEAP_NEWSIZE = “800M” если 8 ядер, по 100М на каждое ядро (если 4 ядра - оставь 800).
Это практически шардинг из коробки. Без этой настройки у вас кластер будет через пень колода.
Ключи для каждого узла можно рассчитать при помощи утилиты, написанной на Python, подавая на вход число узлов в кластере командой ./tokengentool N. Или воспользуйтесь простой формулой для этого: i * (2**(возведение в степень)127 / N), где i - номер узла в кластере, а N - общее число узлов.
Помните об этом параметре при масштабировании кластера.
Hi, guys.
I'm Alexey Zinoviev.
We test some clusters as Aerospike, CouchDB, MongoDB and Cassandra.
We have
Four servers machines:
CPU: 4 x Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
Three client machines:
We have deal with YCSB benchmarks.
Load data (100 GB, more than sum of RAM on 4 nodes, read data, update data, mix queries).
We want big throughoutput for cassandra.
Now, we have 20 - 25 K for one node per second.
I configured Cassandra in file cassandra.yaml.
Please, verify my settings. May be I have big mistake in changing of properties.
I write some settings which I have changed:
And what about some properties in cassandra-env.sh?
I rewrite
#MAX_HEAP_SIZE = “15G” (1/2 from Heap memory)
We created keyspaces also with strategy_options = {replication_factor:2};
If you know more optimal configuration, please send me letter with it.
Thank you
Кассандре в обычном режиме работы (отсутствие compaction, добавление нового узла) нужно иметь запас как минимум 50% диска, потому что ближайший compaction может временно удвоить, а процесс repair в неудачных случаях и утроить потребляемое место. Поэтому мы взяли обьем диска с тройным запасом (у нас получились 300G)" - это отсюда.
Следовательно, необходимо указать разные директории для
commitlog_directory и data_file_directories, saved_caches_directory.
commitlog_sync_period_in_ms = 100000, а не 10 000 (реже сбрасываем на диск)
Это в файликах Cassandra/conf/cassandra.yaml
Также стоит исправить в файлике Cassandra/conf/cassandra-env.sh параметры (лучше на всех узлах). Эти настройки важны для JVM [Java Virtual Machine].
MAX_HEAP_SIZE = “15G” - 1/2 от доступной памяти на каждом узле.
HEAP_NEWSIZE = “800M” если 8 ядер, по 100М на каждое ядро (если 4 ядра - оставь 800).
Ключи, initial token.
Не забудьте изменить параметр initial token в каждом узле в файлике cassandra.yaml.Это практически шардинг из коробки. Без этой настройки у вас кластер будет через пень колода.
Ключи для каждого узла можно рассчитать при помощи утилиты, написанной на Python, подавая на вход число узлов в кластере командой ./tokengentool N. Или воспользуйтесь простой формулой для этого: i * (2**(возведение в степень)127 / N), где i - номер узла в кластере, а N - общее число узлов.
Помните об этом параметре при масштабировании кластера.
Результаты тестирования
Cassandra стабильно умела загружать данные (load data) с двух клиентов 40 - 45 тысяч insert в секунду при загрузке 100M записей по 1Кб. (100 Гб) со средним временем отклика 0.67 ms.
Однако в том, что касается тестов на чтение я наблюдал экспоненциальный рост avg latency при увеличении скорости в районе 10-12K ops. С обновлением дела обстояли лучше, там линейный рост с незначительным наклоном. Но вот max latency также начинал стремительно расти на 12 - 15K ops.
Число ошибок было исчезающе малым, часто 0. Однако, при насильственном гашении узла и обратном его подключении, без замены ключей мы получали упавшего клиента в течение довольно короткого времени.
Более подробные результаты исследования будут выложены позднее.
А вот другие люди тестировали схожим образом.
Мое письмо парням из Cassandra
Hi, guys.
I'm Alexey Zinoviev.
We test some clusters as Aerospike, CouchDB, MongoDB and Cassandra.
We have
Four servers machines:
CPU: 4 x Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
RAM: 31.2 GB
SSD: 4 x INTEL SSDSA2CW120G3, 120 GB full capacity, 94 GB over-provisioned size
HDD: ST500DM002-1BD142, 500 GB, SATA III, 7200 RPM
Three client machines:
CPU: 4 x Intel(R) Core(TM) i5-3470 CPU @ 3.20GHz
RAM: 3.7 GB
HDD: ST500DM002-1BD142, 500 GB, SATA III, 7200 RPMWe have deal with YCSB benchmarks.
Load data (100 GB, more than sum of RAM on 4 nodes, read data, update data, mix queries).
We want big throughoutput for cassandra.
Now, we have 20 - 25 K for one node per second.
I configured Cassandra in file cassandra.yaml.
Please, verify my settings. May be I have big mistake in changing of properties.
I write some settings which I have changed:
Initial
token space 2^127 / 4 (Initial tokens for 4 servers are generated by
this tool: https://raw.github.com/
Commit logs on separate disk (commitlog_directory and from data_file_directories are on different disks)
Concurrent reads: 32 (8 * 4 cores)
Concurrent writes: 32 (8 * 4 cores)
commitlog_sync_period_in_ms = 100000
And what about some properties in cassandra-env.sh?
I rewrite
#MAX_HEAP_SIZE = “15G” (1/2 from Heap memory)
We created keyspaces also with strategy_options = {replication_factor:2};
If you know more optimal configuration, please send me letter with it.
Thank you
Буду ждать ответа. Может подскажут какие там еще настройки сложные есть.


Комментарии
Отправить комментарий